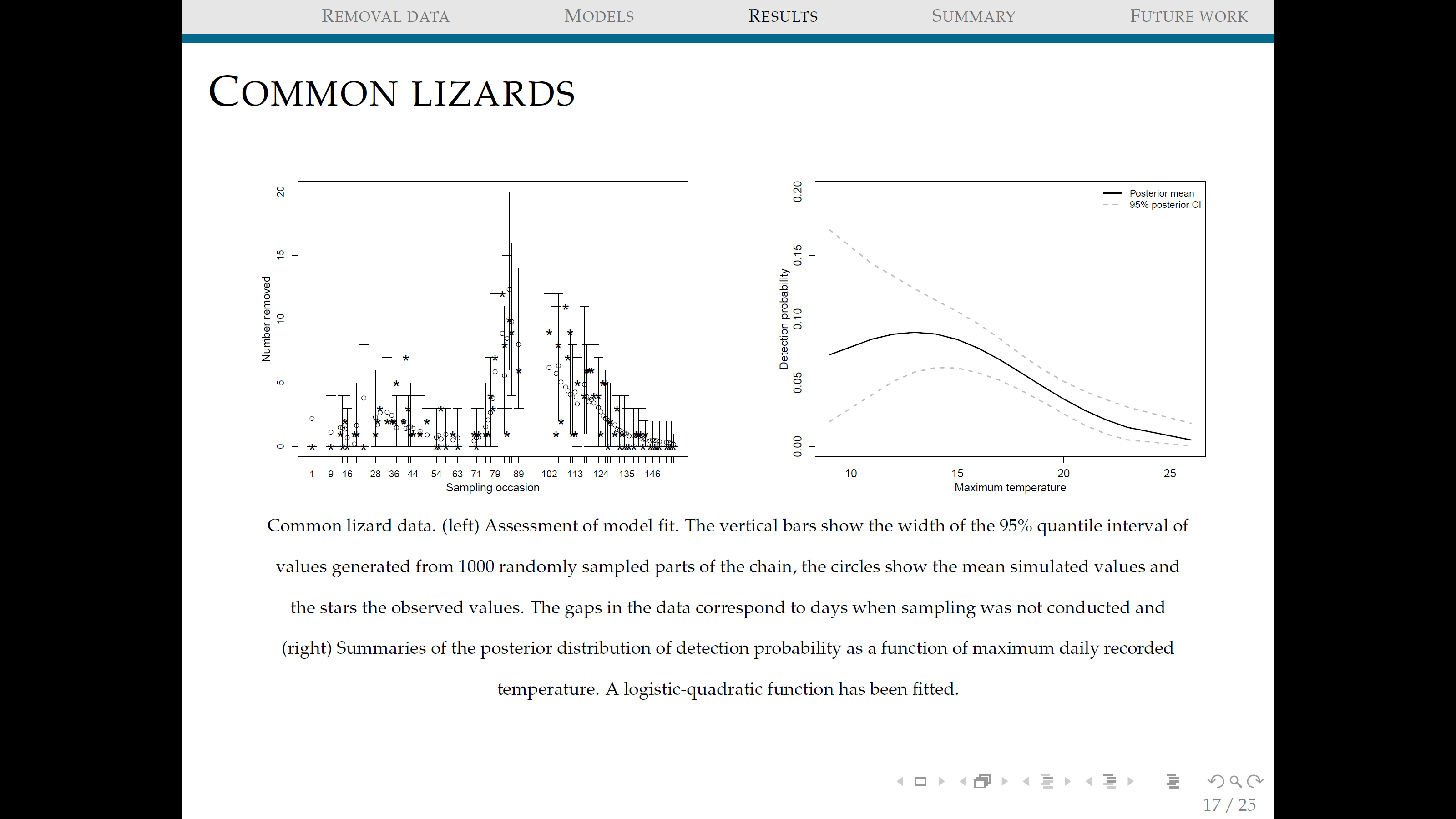
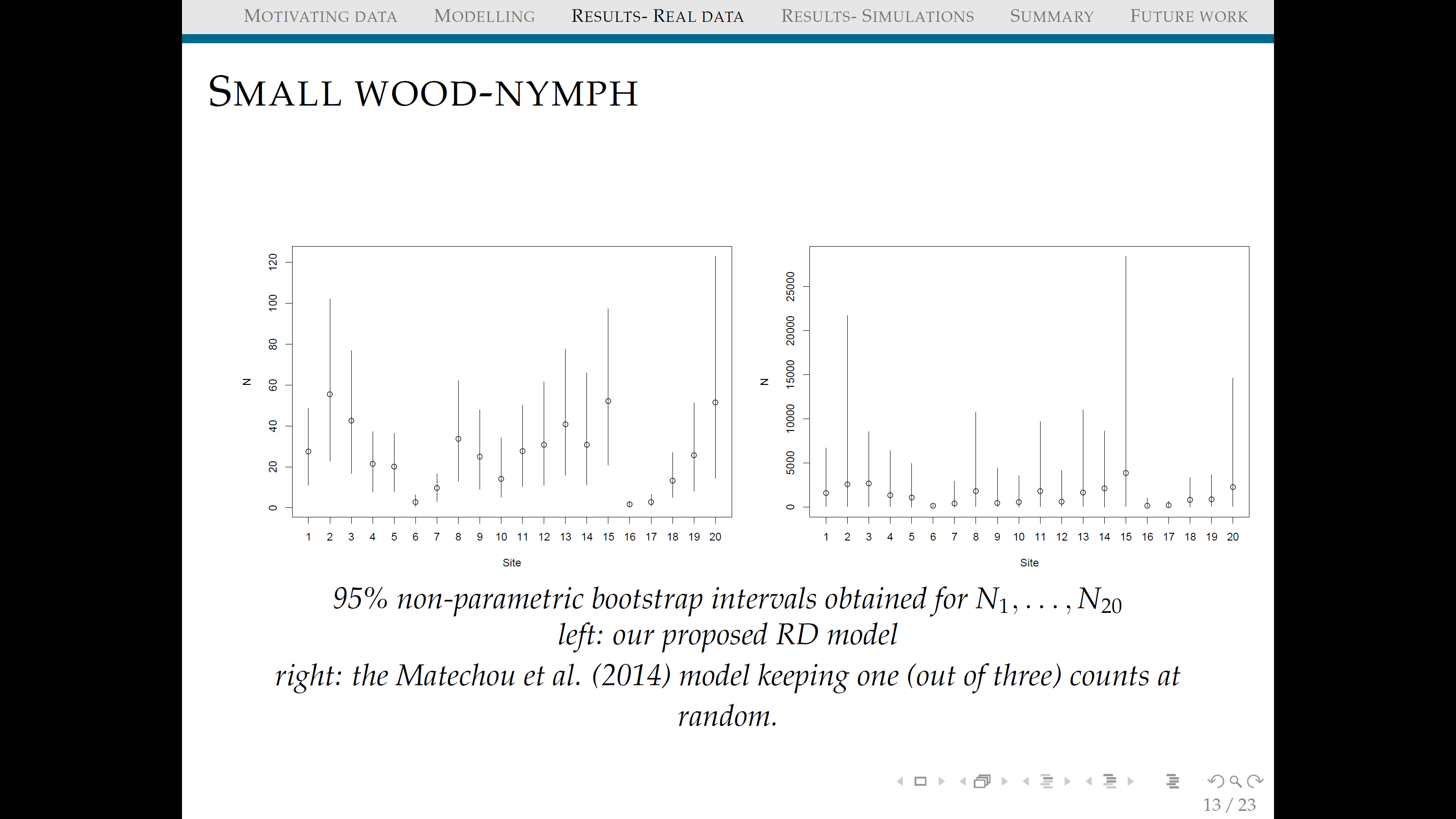
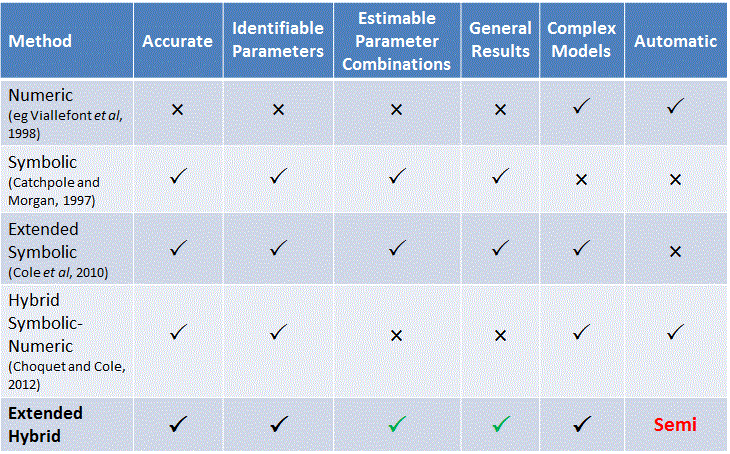
The paper
Temporally varying natural mortality: Sensitivity of a virtual population analysis and an exploration of alternatives
by
Shanae Allen, William Satterthwaite, David Hankin, Diana Cole and Michael Mohr
will appear in Fisheries Science, and is available online early at http://www.sciencedirect.com/science/article/pii/S0165783616302958
Abstract:
Cohort reconstructions (CR) currently applied in Pacific salmon management estimate temporally variantexploitation, maturation, and juvenile natural mortality rates but require an assumed (typically invariant)adult natural mortality rate (dA), resulting in unknown biases in the remaining vital rates. We exploredthe sensitivity of CR results to misspecification of the mean and/or variability of dA, as well as the potentialto estimate dAdirectly using models that assumed separable year and age/cohort effects on vital rates(separable cohort reconstruction, SCR). For CR, given the commonly assumed dA= 0.2, the error (RMSE) inestimated vital rates is generally small (≤ 0.05) when annual values of dAare low to moderate (≤ 0.4). Thegreatest absolute errors are in maturation rates, with large relative error in the juvenile survival rate. Theability of CR estimates to track temporal trends in the juvenile natural mortality rate is adequate (Pearson’scorrelation coefficient > 0.75) except for high dA(≥ 0.6) and high variability (CV > 0.35). The alternativeSCR models allowing estimation of time-varying dAby assuming additive effects in natural mortality,fishing mortality, and/or maturation rates did not outperform CR across all simulated scenarios, and areless accurate when additivity assumptions are violated. Nevertheless an SCR model assuming additiveeffects on fishing and natural (juvenile and adult) mortality rates led to nearly unbiased estimates of allquantities estimated using CR, along with borderline acceptable estimates of the mean dAunder multiplesets of conditions conducive to CR. Adding an assumption of additive effects on the maturation ratesallowed nearly unbiased estimates of the mean dAas well. The SCR models performed slightly betterthan CR when the vital rates covaried as assumed. These separable models could serve as a partial checkon the validity of CR assumptions about the adult natural mortality rate, or even a preferred alternativeif there is strong reason to believe the vital rates, including juvenile and adult natural mortality rates,covary strongly across years or age classes as assumed.