You have a room at home that you feel could really do with redecorating.
You just know it needs doing but you have all kinds of things that always seem to get in the way. You know… going to work, eating, sleeping, tweeting about what you’re watching on tv, tai-chi classes…
And you know that the only way you’ll ever start is to go to the DIY shop and buy a few sample paint pots and a cheap brush. Doing something no matter how small starts you along a path that pretty soon is hard to back out of. And that’s a Good Thing by the way.

Well that’s kind of where we’re at in our webdev team. Only in our DIY metaphor the room is more like a fairly large house. OK forget the metaphor. It’s a website with 100k pages and 150+ publishers, in fact.
A while ago we decided to run a team hack sprint to help us get those “sample paint pots” and kick off a review of our website and our publishing model.
The hack sprint would be just a few days trying to find out who the university publishers are, what they’re trying to achieve, and how they do it. And then building something very basic which fits just maybe one or two of many user needs that we’d gather.
This blog post is an overview of the processes we went through to develop our SLIM prototype (see video below). In later posts I’ll be writing in more detail about those stages and processes.
Some background: the current publishing model
Our current publishing model is pretty simple. Publishers use Dreamweaver to generate static content on a web server. This static content gets built up into a web page on demand with an in-house PHP templating engine that we call Pantheon.
This approach works pretty well most of the time because of its simplicity. But there is a sense that it requires quite a lot of support and training. The overall goal of our hack sprint was to take a step back and briefly review the current situation while also trying out a few design and lean UX techniques.
Who are our publishers?
Our first problem was simply to find out who our web publishers were.
It sounds terribly basic, but we have around 150–200 active publishers in dozens of departments. We ended up calling, going out and talking to something like 30 people. So that’s about 20%. We felt this was a pretty good sample.
Note that we did not want to run focus groups at this stage. Focus groups have their uses, but at this point we just wanted to find out the basics of what people were doing, how they interacted with other people in their publishing teams, even the physical spaces they had to work in.
The goal of the interviews was to find out what roles these people had, how much time they spent on publishing, how much support they needed with the current model, and generally how it worked for them.
We wrote up a little script to guide each team member in asking the same kinds of questions. Then we wrote it all up in a spreadsheet. It was kind of fun. In fact I’ve yet to meet anyone who finds it a pain going out and talking to people about how they use a product or service. And it always throws up surprises…
Hack day 1 – the Karen, Sara, and Mike personas
Gathering user needs is great, but you end up with a lot of data.
Personas help in distilling that data into simple stereotypes that stakeholders and developers can easily latch onto and use as a common point of reference.



I won’t go into detail in this blog post but basically we spent a day going through all the user needs in some detail, and coming up with three personas (“Karen”, “Sara”, and “Mike”). We then focussed on one particular user need that was common to two of the personas:
I want to be able to edit a web page in a simple way that isn’t intimidating to someone like me. I’m not technical and I don’t have much time. Editing web pages isn’t my main job!
Hack day 2 – inspiration and prototyping
We started day 2 with some very simple sketching, rough storyboarding, and then some paper prototypes.
This process was really useful in setting the basic parameters for what we were going to develop.
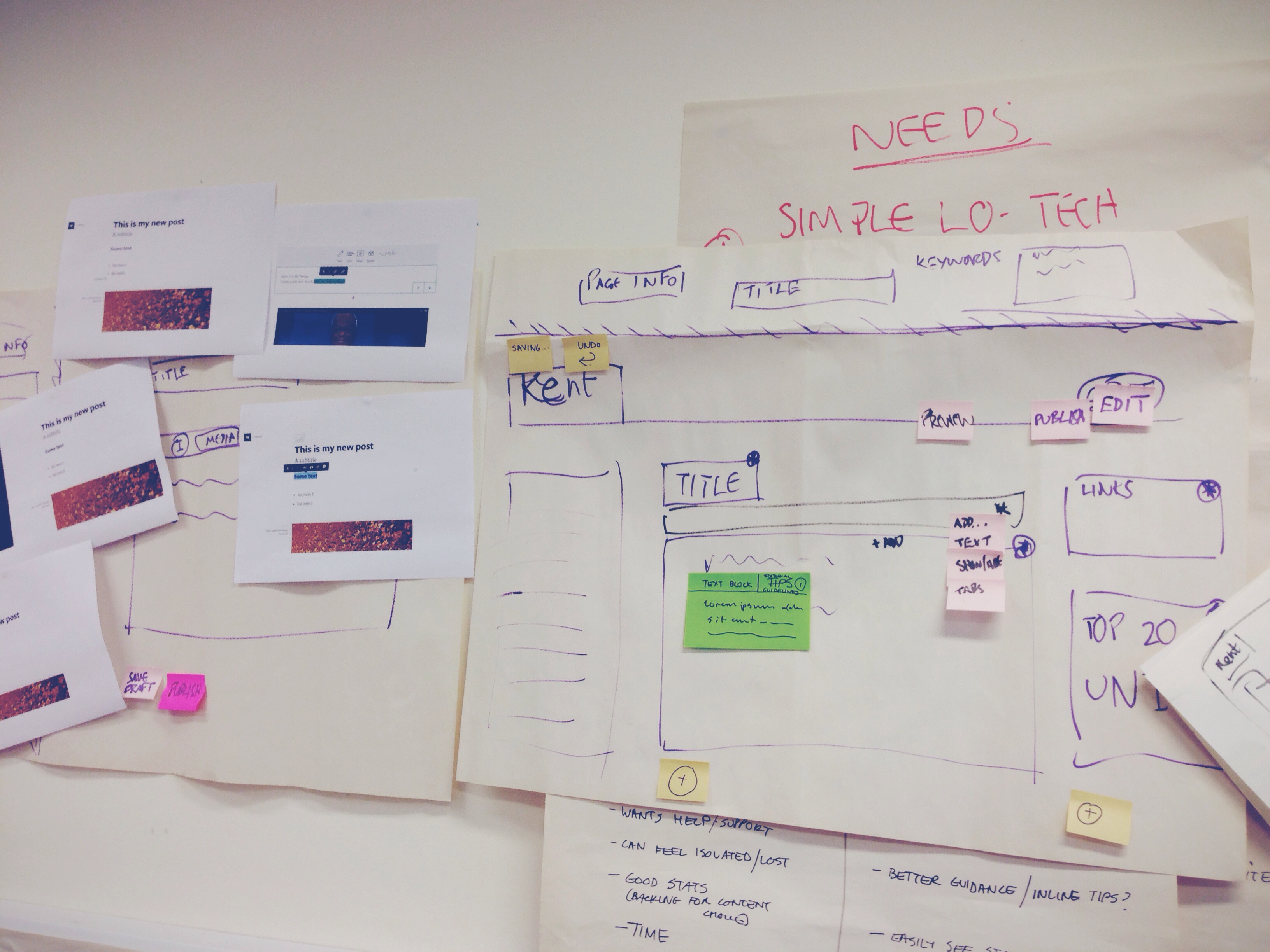
To me the really surprising thing was how sketching made it clear that each developer had a different understanding of how a solution would work.
So after quite a lot of discussion and further sketching we came up with a single idea that we were happy with.
Hand in hand with this was the idea of building inspirations. That is, a list of websites or tools that we would take inspiration from.
The key inspirations for us were:
- medium.com – a gorgeously simple blogging tool by Ev Williams, the guy who brought you blogger and twitter. The focus here is on content. No widgets or tag clouds or whatnot. Just content. Yes, I know it’s a crazy idea to think that people might actually be interested in what you have to say, but maybe it takes people like Ev to push the boundaries a little.
- the Sir Trevor editor.
Hack day 3 – building
Luckily for us the Sir Trevor editor is freely available on github so it was pretty easy for us to set up a basic editor.
One of the things we planned during the sketching phase was to have a multi-column layout. So this required a little bit of tweaking because Sir Trevor didn’t have this by default.
A second concern with Sir Trevor was that text editing wasn’t as nice as in medium.com. The medium.com source isn’t available, although a few people have tried to duplicate some aspects of it. We found a handy little tool called grande.js which we were able to integrate into Sir Trevor.
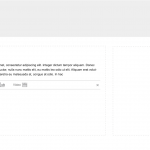
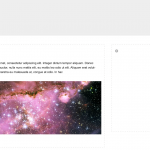
The result was SLIM (Slim Little Internet Maker, or is that Shiny Little Internet Maker? We haven’t decided whether to have a recursive name or not yet).
SLIM is a simple but attractive text editor which saves content into json data files, and which allows blocks of text or images to be dragged around and reordered in a multi-column environment.


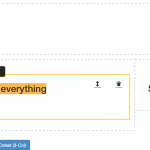
You can find our code in our slim github repo.
We didn’t have the time to get anything more than a very rough user interface, although we do have some designs for how the interface might look if we had a few more days to work on this.

Next steps
This was a 3-day team hack event, with a couple of days added on for user interviews.
We won’t be building on the code we developed in the hack sprint, although we will take away the ideas and processes we adopted. The sprint demonstrated to us that:
- we have a range of web publisher needs but that these can be condensed to a fairly small set of personas and key needs.
- the tools are there to produce a simple and attractive web-based content editor which can be used to store content in an API-friendly way for re-use on a web frontend. Sadly we weren’t able to do any user testing on our finished product.
- as a team we can use techniques like personas, inspiration boards, sketching, storyboarding, and paper prototyping to help smooth the process of converting user needs into a finished product which satisfies those user needs rather than meeting perceived needs.
And above all we had fun!