
We all rely heavily on some unseen infrastructure to make our pretty green padlocks work so we can trust that we’re really talking to our university or bank’s website. It’s so unseen that the Developer Tools in browsers such as Chrome or Firefox and the verbose setting in curl don’t even report it happening. It’s not even managed by or obviously connected to the remote service yet its job is to tell you (well, normally your browser) whether or not the digital certificate that proves it really is your bank hasn’t been revoked.
We don’t normally notice it’s even happening and, because it’s so hidden away, when it goes pear-shaped it’s not very clear what’s gone wrong…
One day in August we started getting reports of some of our services “going slowly” but nothing obvious was wrong with the underlying systems and it wasn’t affecting everyone. The next day, some internal services started having issues talking to our main LDAP directory yet, again, nothing seemed to be wrong with the underlying service.
We eventually tracked down the issue to the OCSP check done as part of the TLS/SSL negotiation taking too long or failing. This is the part of the security check when connecting to a service that ensures that the certificate used by that service hasn’t been revoked. Disabling OCSP checking for this internal system made the timeouts go away.
It wasn’t until later that we made the connection of needing to disable OCSP with reports of the website “going slowly”. Some further checks of manually making OCSP requests to our certificate issuer (COMODO) showed that they were not being serviced in a timely manner which was having all sorts of interesting knock-on. Interestingly, connections via IPv6 were OK but traditional IPv4 connections were, mostly, failing to return any response.
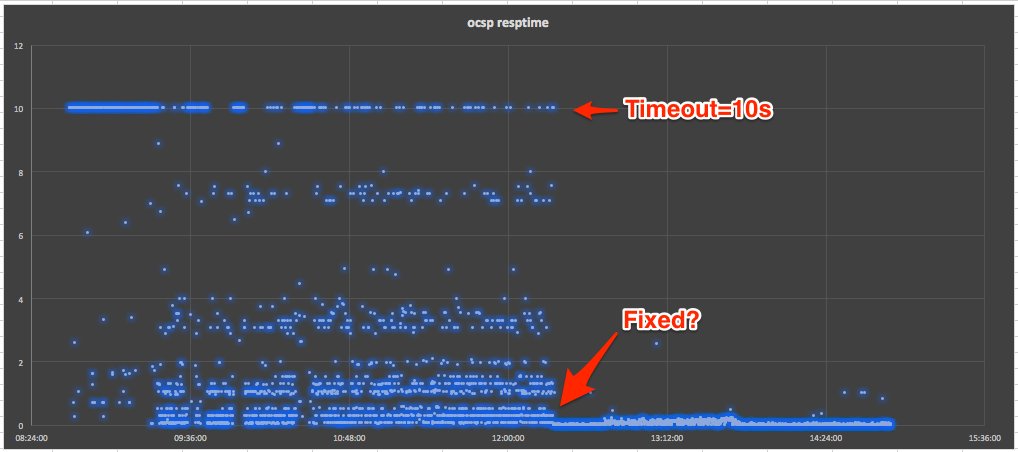
We set up automatic monitoring of the OCSP endpoint to measure response times and discovered that most IPv4 requests were not returning a response within 10 seconds and virtually none were returning in less than 2 seconds.
The COMODO status pages had a note about some DDOS attacks causing issues but implied that they had been resolved. While we had tickets logged with upstream support, COMODO themselves were saying little about the problem so there was little we could directly do as the problem lay with the OCSP (and CRL) endpoint(s).
With UCAS Results Day (Clearing/Adjustment) looming down on us but a few days away we decided to replace the affected certificates with some from a new provider which made the issue go away for us. We continued to monitor the COMODO situation. A few hours later, the monitoring showed that COMODO had fixed the problem:
While we had a get-out-of-jail free card in our ability to quickly get new certificates from a new issuer, that only served to hide the real issue of how our relationship with a certificate vendor continues for the life-time of the certificate (for us, normally 3 years). As customers we require the revocation services to be as resilient as the services we’re offering and, when they aren’t, there’s nothing we can easily do about it.
If the issue had happened a few days later then our main website, despite all the work we’ve done to make it resilient, would have been at best sluggish — and at worst inaccessible — to many potential applicants and we would likely have lost new students. There are some things we can do to mitigate this (OCSP Stapling) but we’d not considered these before and some services (such as LDAP) don’t seem to support it anyway.