
Following the technical sprint the project has been able to deliver a working model of the Programmes administration application to the customer.
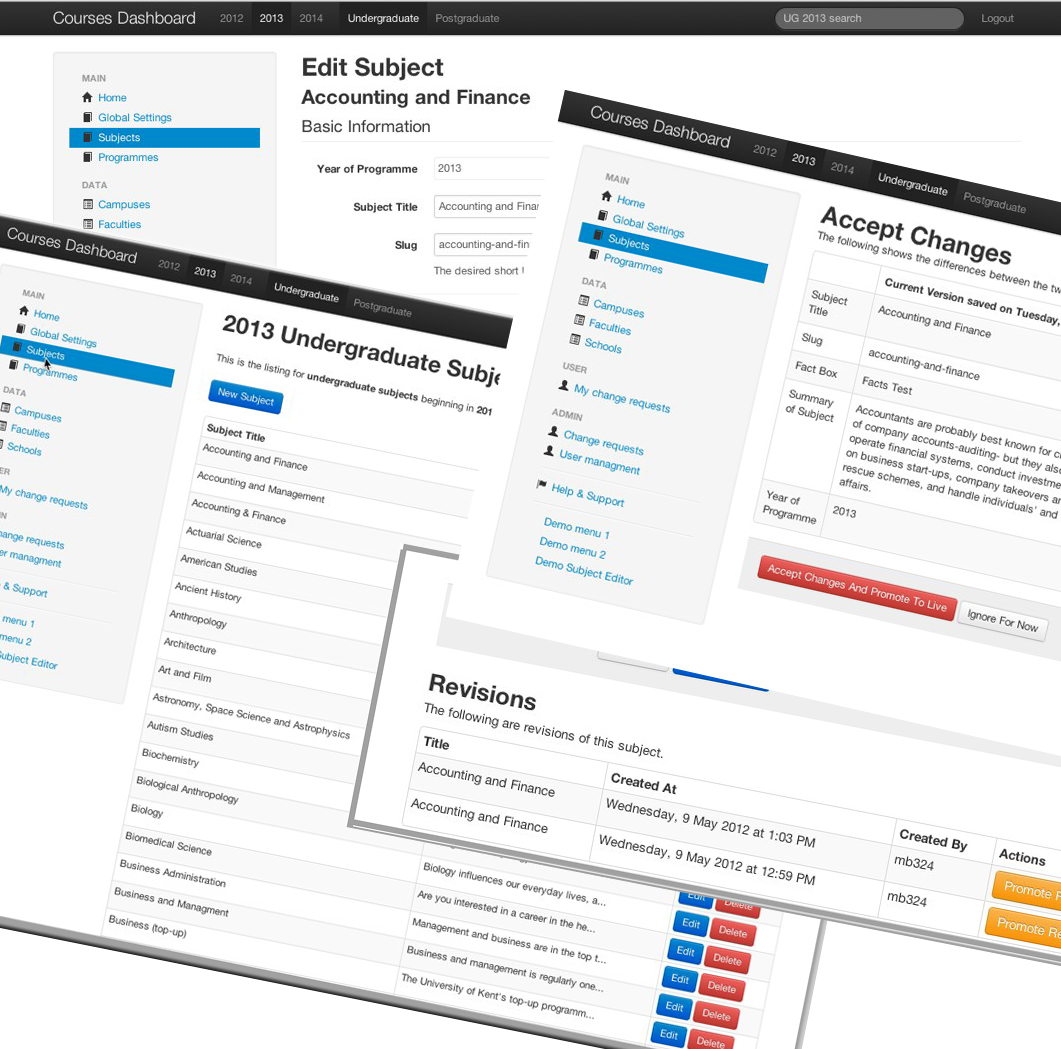 A great deal of work has gone into the project since its beginning but it felt like a significant milestone was reached this week. The work of the second technical sprint drew on the groundwork previously completed in compiling user stories from discussion with the stakeholders and making a great effort to understand the customer requirements. Mark Fendley did sterling work in marshalling this work and creating the story cards – a master Scrum master. We had committed to delivering wireframes for homepage and data entry screens and a minimum viable product – a working model with at least five editable fields. However the time invested in evaluating the best platform and framework for the application really paid off allowing the developers to leapfrog over many of the wireframes and produce a working model with a really good looking user interface. The initial feedback from the customer has been really positive and this great job from the development team has really boosted the project.
A great deal of work has gone into the project since its beginning but it felt like a significant milestone was reached this week. The work of the second technical sprint drew on the groundwork previously completed in compiling user stories from discussion with the stakeholders and making a great effort to understand the customer requirements. Mark Fendley did sterling work in marshalling this work and creating the story cards – a master Scrum master. We had committed to delivering wireframes for homepage and data entry screens and a minimum viable product – a working model with at least five editable fields. However the time invested in evaluating the best platform and framework for the application really paid off allowing the developers to leapfrog over many of the wireframes and produce a working model with a really good looking user interface. The initial feedback from the customer has been really positive and this great job from the development team has really boosted the project.
Of course these are early days in the development of what we are currently calling the Programme Plant but this is a good start. Currently the model only exists on a webteam laptops so cusotmers have not been able to get any hands on experience. A component needed by the application was not available on the server so we had to compromise. This component will be inplace by mid-June prior to the next technical sprint. In the next sprint we will begin load testing – something we are committed to doing at every stage of the development.
Those interested in some technical detail on the experience of the developers in working with the chosen platform – PHP on a Laravel framework – are recommended to check Matt Bull’s blog and comments from others which can be found here: Webdev blog
This week we will present the working model to other stakeholders and seek further feedback. We are committed to incremental development and will spend some time before the next sprint – which begins on 14th June – analysing feedback and looking again at the users stories.
Well done to all involved in the project!






