
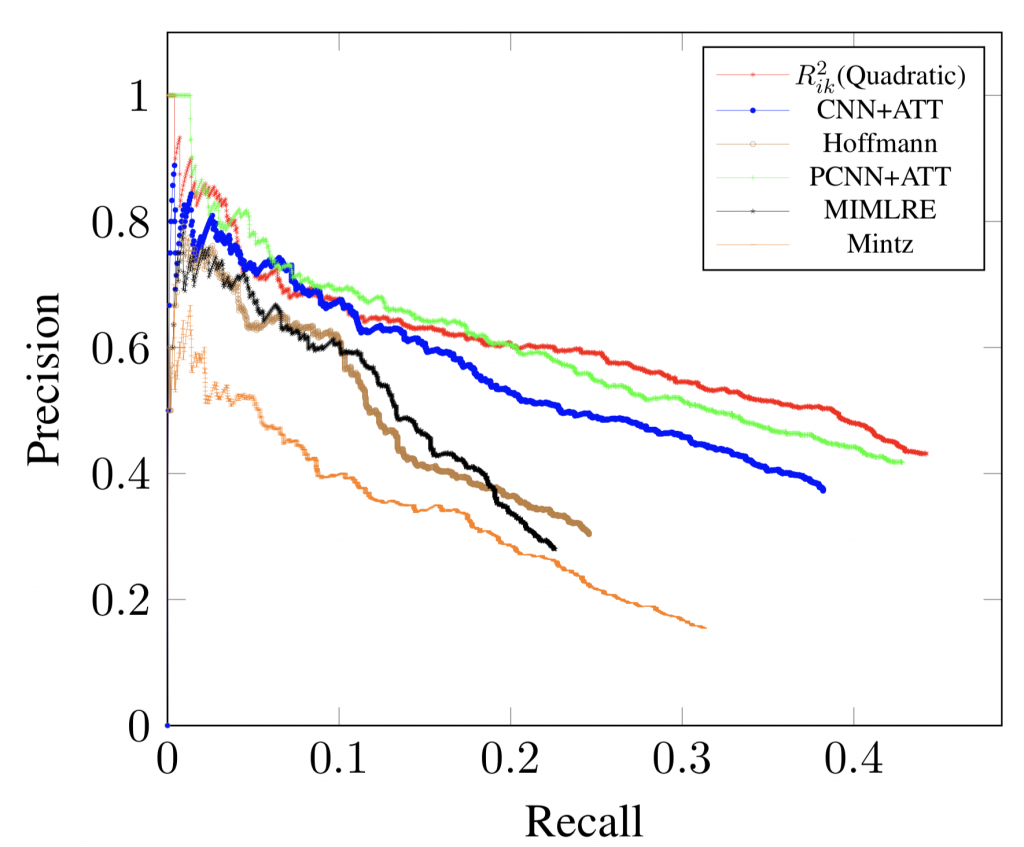
In this paper, we showed how we can learn relations in an unsupervised way using a simple, but Mathematically elegant model, which shows comparable performance against sophisticated neural network models. This paper will soon appear at ACL-2018 conference as a full paper.
About ACL: The Association for Computational Linguistics (ACL) is the premier international scientific and professional society for people working on computational problems involving human language, a field often referred to as either computational linguistics or natural language processing (NLP). The association was founded in 1962, originally named the Association for Machine Translation and Computational Linguistics (AMTCL), and became the ACL in 1968. Activities of the ACL include the holding of an annual meeting each summer and the sponsoring of the journal Computational Linguistics, published by MIT Press; this conference and journal are the leading publications of the field. The 56th Annual Meeting of the Association for Computational Linguistics will be held in Melbourne, Australia at the Melbourne Convention and Exhibition Centre from July 15th to 20th, 2018.
Abstract: Word embedding models such as GloVe rely on co-occurrence statistics to learn vector representations of word meaning. While we may similarly expect that co-occurrence statistics can be used to capture rich information about the relationships between different words, existing approaches for modeling such relationships are based on manipulating pre-trained word vectors. In this paper, we introduce a novel method which directly learns relation vectors from co-occurrence statistics. To this end, we first introduce a variant of GloVe, in which there is an explicit connection between word vectors and PMI weighted co-occurrence vectors. We then show how relation vectors can be naturally embedded into the resulting vector space.
Five key highlights:
- Traditionally, relation extraction systems have relied on a variety of linguistic features, such as lexical patterns, part-of-speech tags and dependency parsers.
- Unlike traditional word embedding models, in our model, word vectors can be directly interpreted as smoothed PMI-weighted bag-of-words representations.
- We represent relationships between words as weighted bag-of-words representations, using generalizations of PMI to three arguments, and learn vectors that correspond to smoothed versions of these representations.
- Our model characterizes the relatedness between two words by learning a relation vector in an unsupervised way from corpus statistics.
- What is so remarkable about our model is that, it is conceptually much simpler, and has not been specifically tuned for relation extraction task.
More details can be found in our ACL-2018-camera-ready which will soon appear in the proceedings.
Authors: Shoaib Jameel, Zied Bouraoui, and Steven Schockaert